ダイクストラ法とは、グラフ上の最短経路問題をとくアルゴリズム。↓このページに詳しいアルゴリズムの説明がある。
cf. ダイクストラ法(最短経路問題) – deq notes
Ruby でやってみた。
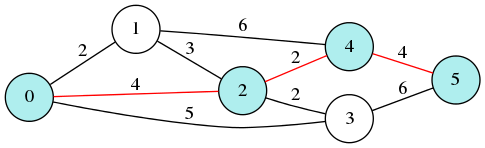
例題は、上のページにもあるこのグラフ(ただしノードにつけた番号のせいか上下が逆になっている)。
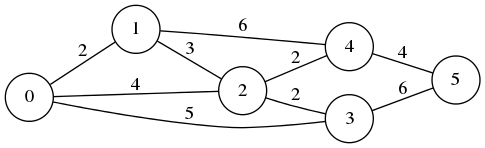
円(ノード)に番号がふられ、ノードをつなぐ辺(エッジ)にはそこを通るときのコスト(距離とも時間とも解釈できる)が付されている。この中の任意の 2 つのノードをつなぐ最短経路とコストを求めるのが最短経路問題だ。
今回は 0 番のノードをスタートし 5 番のノードをゴールとする最短経路とそのコストを求めてみる。
#!/usr/bin/env ruby
# encoding: utf-8
class Node
attr_reader :name
attr_accessor :done, :cost, :from
def initialize(name)
@name = name
@edges = []
@done = false
@cost = nil
@from = nil
end
def add_edge(edge)
@edges << edge
end
def each_edge
@edges.each{|e| yield(e) }
end
end
Edge = Struct.new(:dest, :cost)
def make_edge(nodes, a, b, cost)
nodes[a].add_edge(Edge.new(b, cost))
nodes[b].add_edge(Edge.new(a, cost))
end
nodes = []
0.upto(5) do |i|
nodes << Node.new(i)
end
edges = [
[0, 1, 2], # [node_a, node_b, cost]
[0, 2, 4],
[0, 3, 5],
[1, 2, 3],
[2, 3, 2],
[1, 4, 6],
[2, 4, 2],
[4, 5, 4],
[3, 5, 6]
]
edges.each do |a, b, cost|
make_edge(nodes, a, b, cost)
end
start = 0
goal = 5
start_node = nodes[start]
start_node.cost = 0
start_node.done = true
start_node.each_edge do |edge|
n = nodes[edge.dest]
n.cost = edge.cost
n.from = start_node.name
end
while true do
done_node = nil
nodes.each do |node|
if node.done || node.cost.nil?
next
else
node.each_edge do |e|
n = nodes[e.dest]
if n.cost.nil?
n.cost = node.cost + e.cost
n.from = node.name
else
if node.cost + e.cost < n.cost
n.cost = node.cost + e.cost
n.from = node.name
end
end
end
if done_node.nil? || node.cost < done_node.cost
done_node = node
end
end
end
done_node.done = true
break if nodes.all?{|n| n.done }
end
puts nodes[goal].cost
route = [goal]
begin
node = nodes[route.first]
route.unshift(node.from)
end
until route.first == start
puts route.map(&:to_s).join(" -> ")
実行結果:
takatoh@nightschool $ ruby dijkstra.rb 10 0 -> 2 -> 4 -> 5
というわけで、最短経路は 0 -> 2 -> 4 -> 5、コストは 10 という答えが得られた。これは上のリンク先の答えと同じなので、あっていると思っていいだろう。